基于指令微调的信息抽取大模型构建
迈向泛化和实用的通用抽取模型
具体Presentation可以看我的B站视频,更为完整。bilibili.com/video/BV1qW4y1Z7ZA/ B站视频PPT的分享链接。
研究动机及本工作的差异性
在信息抽取和知识图谱的构建任务中,主要面临着四个主要的问题:
- 任务的多样性和结构复杂性。我们有不同的抽取任务需求,这些任务有着不同的抽取内容要求,且结构复杂,例如实体、关系、事件等。每一种任务都需要特定的抽取技术,以满足任务的特定需求。
- 领域需求特定。不同领域的抽取要求不同,需要根据具体的领域,设计不同的模型和数据集。如医疗领域需要关注疾病、药物、治疗手段等信息,金融领域关注公司、管理人员、财务事件等信息,舆情领域关注国家、政党、选举等信息,而文化领域则可能关注诗词、语言、典故等信息。
- 数据标注难度。对于一个比较完整的样本,我们需要标注触发词、关系、论元等信息,这需要大量的人力和时间成本。尤其是在没有足够标注数据的情况下,训练一个高效的抽取模型会变得十分困难。当前方法大多依赖于大规模和细粒度的子任务标注,这使得抽取模型难以从科研中走向真正的实用。因为在实际应用中,我们往往难以获得大规模的细粒度标注数据,这会限制模型的性能和应用范围。
最近的自然语言处理技术中,大型语言模型(LLM)已经成为研究的热点,它可以在下游任务中展现出强大的泛化能力。然而,它们目前主要适用于对话领域,而在训练阶段与下游自然语言理解(NLU)任务并不适配。对此,一些研究表明,LLM在信息提取(IE)任务中存在性能差距,表现不如传统技术。传统的生成式抽取方法,如统一的信息提取(UIE)模型可以提高效率,但其需要为不同的下游任务进行单独的finetune,这导致在低资源设置或面对新的标签模式时,UIE表现不佳。此外,USM存在限制,例如将IE转化为语义匹配任务难以与生成语言模型集成,并且需要对每个词进行语义匹配,导致训练和推理时间显著增加。因此,如何构建一个强大的具有较强泛化性的面对信息抽取领域的基础抽取大模型具有较大的研究价值。
为了达成目标,本工作从以下几个方面进行设计:
- 针对于大模型在上下文学习上进行IE的不足,我们使用参数微调的方式增强模型的信息抽取能力
- 为了提高参数微调模型的能力、避免灾难性遗忘,我们构建了多元化的指令数据集
- 为了增强模型对于结构化信息的理解和建模,本文设计了多种数据增强方法构建指令集
- 模型通过指令的方式统一的适配下游任务,并且具有较好的能力和泛化性
系统介绍
目前,ChatGPT 等大型模型主要适用于对话领域,而在训练阶段与下游信息抽取任务的适配性不足。此外,目前的开源模型在 NLU 能力方面还有待提高。然而,大型模型的强大泛化性和涌现能力可以为信息抽取提供强大的支持。因此,我们需要一个强大的、具有较强泛化性的面向信息抽取领域的基础抽取大型模型。
整个系统的构建可以分为三步:收集丰富的数据构建数据池,通过数据增强等方法构建多样化的指令池,通过多任务指令微调的方法使模型能够适用于生成结构化输出。我们期望模型能够适配于下游的各类信息抽取任务,并且在未知数据集上同样表现出较强的泛化能力。
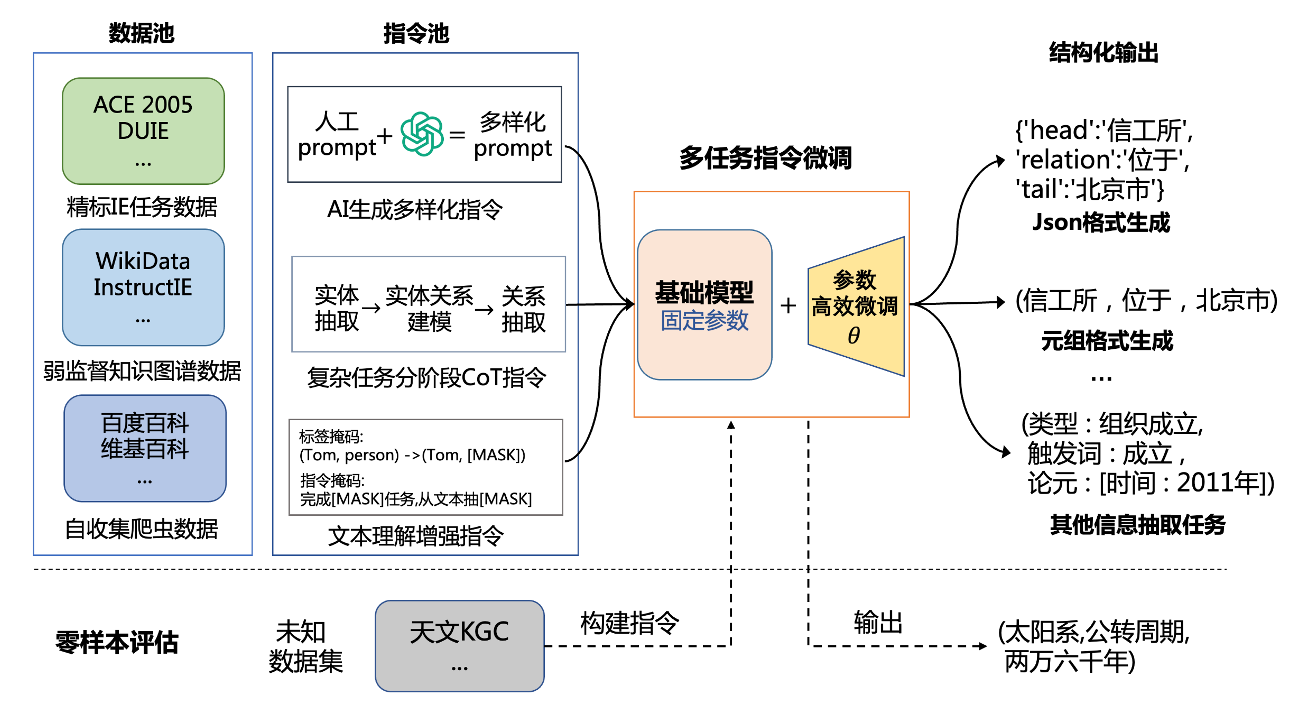
我们选择了 ChatGLM 和 LLaMA 作为基础模型,因为它在对话领域已经展现出了强大的性能,体现出较好的指令跟随能力。GLM 中英文预训练语料都非常平衡,适合完成中英文任务。LLAMA有加大的参数,但是由于缺失中文能力,需要先对模型使用大量任务语料进行全参数微调。我们面向信息抽取任务采用了 Ptuning(Liu at el. , 2023) 和 Lora(Hu at el. , 2023) 的高效微调方法,并构建了多任务指令微调数据集。在构建指令数据集的过程中,使用了一系列的方法来扩充指令的丰富程度:
1.数据集扩充
- 收集精标任务数据、弱监督图谱数据、爬虫数据
- 将图谱数据和关系抽取数据转化为KGC任务数据
- 对剩余信息抽取数据进行分类整理
2.数据集去噪
- 挖掘训练集中Schema对数据集进行优化
- 清洗任务数据集
- 将数据集转化为文本到文本格式,并对齐语义标签
3.指令构建和增强
- 设计更丰富的子任务
- 将复杂任务分解为简单任务:如三元组抽取分解为命名实体识别+关系抽取
- 设计文本理解增强任务:给定输出结果,让模型预测输入指令;遮盖部分指令和输出结果,让模型从中填充
- 设计更多元化的指令
- 人工设计指令种子,使用GPT生成多样化指令
- 设计更多元化的生成方式
- 对同一个样本构造多种不同的输出格式
- {'head':'', 'relation':'', 'tail':’’}
- 关系:头实体,尾实体\n
- 头实体->关系->尾实体
- 增添无关样本,缓解幻觉
- 在指令中添加无关关系类型,让模型学会拒绝生成
通过微调,我们实现了以下提升:
- 提高了复杂指令的跟随能力。
- 提高了生成结构化信息的能力。
- 提高了生成信息的完整性。
- 提高了面向特定任务的性能。
有待提高:尽管我们已经取得了一些进展,但仍有一些问题需要解决:
- 生成的信息不完全。
- 存在错误生成和幻觉问题。
- 对指令的理解和跟随存在错误。
整体流程
数据集构建
数据源
IE 指令数据
IE INSTRUCTIONS (Gui et al., 2023)收集了 32 个公开可用的数据集,涵盖三种类型的 IE 任务:NER、RE 和 EE。为了确保数据集的多样性,除了新闻和维基数据等一般领域的资源外,我们还包括来自科学、医疗保健、社交媒体和交通等各个领域的语料库。InstructUIE
CCKS InstructionKGC
CCKS InstructionKGC 比赛发布5000条左右的知识图谱数据作为训练集。这5000条数据是使用维基数据对中文维基百科进行远程监督标注的弱监督数据,每行是一个 json 串,具体字段内容如表所示。(Wang et al., 2023) CCKS2023 开放环境下的知识图谱构建与补全
自收集数据
我们在网络上各平台抓取了大量信息抽取任务数据。我们将不同的数据集按照任务进行分类,清洗。在构建数据集的过程中,我们大致保证数据的任务种类平衡、领域平衡。最终我们将所有数据集的格式统一成序列到序列的生成模型,我们设计了数十个提示模版,将数据集以统一的标准构建为指令集。
| 任务 | 数据集名称 | 语言 |
|---|---|---|
| 关系抽取 RE | ADE_corpus | 英文 |
| 事件抽取 | CCKS2022金融领域FEW-SHOT事件抽取数据集 | 中文 |
| 事件抽取 | GENIAPHEECASIEACE05 | 英文 |
| 事件抽取 | Baidu2020-RE | 中文 |
| 事件抽取 | Baidu2020-EE | 中文 |
| 命名实体识别 | Youku NER Dataset 文娱NER数据集 | 中文 |
| 命名实体识别 | E-Commercial NER Dataset / 电商NER数据集 | 中文 |
| 命名实体识别 | Youku NER Dataset 文娱NER数据集 | 中文 |
| 数据类型 | 语言 | 数据比例 |
|---|---|---|
| 比赛数据集 | 中文 | 40% |
| 弱监督图谱数据 | 中文 | 30% |
| 信息抽取数据 | 英语 + 中文 | 30% |
数据准备
我们数据准备的大致过程为:
- 我们清洗了数据中的特殊标签、表情等冗余信息。删去了文本长度过小的输入,将过长的文本进行切分,保证输入长度在1024个token内。
- 为了适配生成式的语义内容,我们将数据集都转化为文本到文本的形式。我们将带有下划线、缩写或特殊格式的标签也转换为自然语言格式。
- 为了构造指令,我们针对不同任务设计了多个指令模版,根据指令模版和数据比例构建训练集
- 在输入模型前,将指令数据集转化为对应的数据集格式并进行token化
指令构建
指令包括任务说明,约束和输入三个部分。
- 任务说明是一个描述在原始输入文本中需要提取哪些相关信息以及如何提取这些信息的文档。任务说明包含任务的输入类型、提取的信息类型、输出结构的格式以及模型在提取过程中需要遵循的任何其他约束或规则等信息。它为模型提供了理解提取任务并生成准确有意义的输出所需的详细指导。
- 约束是任务的输出标签约束,表示模型可以针对给定输入生成的一组可能输出。这些标签约束特定于每个任务,并提供有关如何将预测输出映射到相应语义概念的信息。选项可以是实体标签、关系类型、事件标签等,这些标签为模型提供了结构化的输出空间,使其能够生成与任务的底层语义结构一致的输出。
- 输入是任务的原始文本输入,是模型需要从中提取相关信息并生成结构化输出的内容。
指令的质量对于知识图谱的泛化性和下游任务性能影响巨大。为了提高指令的多样性,我们提出了一种AI提示的方法。我们首先使用人工编写的指令作为提示种子,然后通过Prompt GPT3.5生成大量的指令提示。这些提示包含更多的语义和信息,能够更好地覆盖真实世界中的各种情况。我们使用人工筛选的方式来选取最优的指令。这种方法减轻了人工编写指令的负担,并同时保证了指令的质量。
考虑到模型在预训练的过程中没有注入结构化的信息生成任务,直接将其用于下游任务的微调存在较大的局限性。为了充分利用模型的预训练效果,我们采用了任务分解的思想(参考Text2Event的课程表学习思想)。具体来说,我们将较为复杂的任务进行分解,并为其引入一些子任务,使得模型能够更好地捕获共同的结构信息,并在此基础上深化对不同语义的理解。例如,在命名实体识别(NER)任务中,我们为其引入了实体跨度提取任务和实体类型任务;在关系提取(RE)任务中,我们为其引入了实体对提取任务和实体对关系识别任务;而在事件提取任务(EE)中,我们引入了触发器提取任务和参数提取任务。这些子任务的引入为模型提供了更多丰富的训练信号,从而提高了模型的性能和泛化能力。
我们还将指令进行转化,构建出不同的增强任务,使模型能够从更多维度上建模文本和结构化信息之间的关系。以下是一个例子:
已知候选的关系列表:['事件', '位于', '名称由来'],请你根据关系列表,从以下输入中抽取出可能存在的头实体(Subject)与尾实体(Object),并给出对应的关系三元组。请按照 (Subject,Relation,Object) 的格式回答。
浅草神社位于日本东京都台东区浅草的浅草寺本堂东侧,供奉的是土师真中知、桧田浜成、桧前武成,三位对于浅草寺创立有密切关联的人,每年5月17日都会举行三社祭。现在被指定为重要文化财产。
(浅草神社,事件,三社祭),(浅草神社,位于,浅草),(台东区,位于,东京都),(浅草寺,位于,浅草),(浅草寺,名称由来,浅草)
---
已知抽取出的三元组:(浅草神社,事件,三社祭),(浅草神社,位于,浅草),(台东区,位于,东京都),(浅草寺,位于,浅草),(浅草寺,名称由来,浅草)。请你根据输入和输入中抽取出来的关系三元组,给出输入中包含的关系列表。请按照['relation', 'relation', 'relation']的格式回答。
浅草神社位于日本东京都台东区浅草的浅草寺本堂东侧,供奉的是土师真中知、桧田浜成、桧前武成,三位对于浅草寺创立有密切关联的人,每年5月17日都会举行三社祭。现在被指定为重要文化财产。
['事件', '位于', '名称由来']
指令微调框架
指令调优是一种多任务学习框架,可以使用人类可读的指令来指导 LLM 的输出。给定源文本和特定于任务的说明,训练模型以生成表示所需输出结构及其相应标签的标记序列。在监督设置中,在所有任务的训练期间提供指令,并且模型针对每个任务的一组标记数据进行微调。这允许模型学习特定于任务的特征并针对每个任务进行优化。在零样本设置中,仅在训练期间为任务的子集提供指令,并且模型在未见过的任务上进行评估,而无需额外的微调。这需要模型对任务进行泛化,并使用从指令调优框架中学习到的共享特征来推断新任务的输出结构。
指令微调框架由两部分组成:基础模型和微调方法。基础模型是在大规模数据集上进行预训练的开源大模型,例如Llama、Bloom等。而微调方法通常是一些高效的参数调整策略,例如Ptuning,Lora等。
在选择基础模型方面,我们认真调研了目前开源的基础模型并整理了一个github仓库https://github.com/Longyichen/Alpaca-family-library,经过广泛的调研,我们选择Llama和ChatGLM作为基础模型。
- Llama是目前最先进的基础大型语言模型之一。它经过对20多种语言的大量未标记数据进行训练,使其非常适合进行各种任务的微调。为进一步提升其中文能力而不破坏原有分布,CaMA基于LLaMA模型,并使用中文语料先对LLaMA(13B)进行全量预训练。在尽可能保留原有英文和代码能力的前提下,CaMA进一步提高了模型对中文理解能力和知识储备的支持。因此CaMA能够适配中文知识图谱构建的下游任务。
- ChatGLM是一个基于大规模语言模型的对话系统,其优势在于其较低的部署门槛、更长的序列长度、以及人类意图对齐训练等方面。ChatGLM-6B是一个中英双语语言模型,训练了1T的token数量。此外,ChatGLM-6B的序列长度达到了2048,相比于GLM-10B的1024,支持更长对话和应用,同时也通过人类意图对齐训练使模型初具理解人类指令意图的能力。因此,在中文信息抽取任务上选择GLM作为基础模型是因为其在部署门槛、序列长度、以及训练能力方面的优势。
在微调方法上,为了降低成本和考虑到可实践性,主要使用两种方式以高效微调的方式让预训练模型适配到下游任务中:
- P-tuning v2是一种通用的微调技术,可以应用于各种自然语言处理任务,例如文本分类、命名实体识别、情感分析等。它与微调的性能相匹配,而只有0.1%-3%的微调参数。P-tuning v2以较小的规模匹配所有任务中的微调性能。在SuperGLUE中,Lester等人(2021)的性能和较小规模的P-tuning可能相当差。相反,P-tuning v2甚至显著优于RTE上的微调。
- LoRA: Low-Rank Adaptation of Large Language Models 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题。目前超过数十亿以上参数的具有强能力的大模型 (例如 GPT-3) 通常在为了适应其下游任务的微调中会呈现出巨大开销。 LoRA 建议冻结预训练模型的权重并在每个 Transformer 块中注入可训练层 (秩-分解矩阵)。因为不需要为大多数模型权重计算梯度,所以大大减少了需要训练参数的数量并且降低了 GPU 的内存要求。研究人员发现,通过聚焦大模型的 Transformer 注意力块,使用 LoRA 进行的微调质量与全模型微调相当,同时速度更快且需要更少的计算。
评估方法
在构建知识图谱方向的研究中,我们采用了多个指标来评估模型的性能,包括F1值、ROUGE-N值以及基于跨度的偏移量Micro-F1。其中,ROUGE-N指标是基于模型生成的输出文本和标准输出文本的N-gram重叠程度,我们选择了N=2来计算模型输出结果与标准结果之间的相似性,并用0.5_1 + 0.5_ROUGE-N的方式将其融合为综合得分。
信息抽取任务聚焦于命名实体识别(NER)、关系抽取(RE)和事件抽取(EE)的评估方法。对于NER任务,我们采用跨度级评估标准来衡量算法的性能,即模型必须正确预测实体边界和实体类型。在RE任务中,我们考虑主体实体、对象实体及它们之间的关系,只有当模型可以准确预测它们的边界关系时,才会被认为是正确的。而在EE任务中,我们评估模型在两个方面的性能:(1)事件触发器的准确性,即模型必须正确识别并预测事件的类型和触发词。以及 (2) 事件参数的准确性,即模型必须将事件参数的角色类型和事件类型与提及的参考参数进行匹配,才能被视为正确。这些评估指标将为我们的实验提供量化的性能表现,可以更准确地比较不同模型在特定任务上的表现。
结果分析
CCKS 图谱构建任务
本实验基于CCKS比赛提供的实验数据和评价标准。
由于和本实验和InstructIE (Wang et al., 2023) 在同样的实验设置,并且InstructIE没有开源训练数据和权重使得实验结果难以复现,因此直接使用Instruct IE论文提供数据作为对比参考。标注Ours的实验结果来自于文本的实验结果。
- MT5:T5 的多语言变体,它在具有 101 种语言的基于 Common Crawl 的新数据集上进行了预训练。InstructIE作者使用了27000条自构建同分布数据进行了微调。
- ChatGPT:OpenAI 的 InstructGPT 的系列模型,针对对话和对齐进行了RLHF的细致微调。
- Alpaca:一个在LLaMA基础上使用 ChatGPT 生成的 52K instruction following demonstrations数据进行微调的模型,有7B和13B两个版本。 InstructIE作者使用了27000条自构建同分布数据进行了LoRa微调。
- ChatGLM:具有62亿参数的中英双语语言模型,基于GLM架构,有着充分的中英双语预训练和更长的序列长度。
- 我们在 LoRa 微调版本,我们只使用了CCKS Instruct KGC 提供的5000条训练集微调5个epoch
- 作为对比,在 P-tuning 版本,我们对数据进行了增强,将5000条训练集数据通过构建和设计指令扩充至25000条,同时加入了中文的 DUIE 数据作为补充
- CaMA:基于LLaMA-13B的模型,在中文和英文语料库上进一步预训练,旨在进一步增强模型的中文能力,同时保留英文能力。本文使用的是13B版本。
- 在LoRa版本中InstructIE作者使用了27000条自构建同分布数据进行了LoRa微调。
- 我们的IECaMA使用了经过数据增强的CCKS Instruct KGC 训练数据,经过增强的英文 InstructUIE 通用任务数据,使用Probing CaMALora获得的5000条图谱构建数据,自收集的数据,其中包含中文的DUIE数据、天池中的各类NER、关系抽取、事件抽取等等。微调数据集经过多元化的指令构建、清洗和筛选,最终保持中英文比例保持2.3:1(为了和CaMA预训练的数据比大致相同,最大程度上保留CaMA的各方面能力)
实验结果如下:
| Techniques | Models | F1 | ROUGE-2 | Score |
|---|---|---|---|---|
| Fine-Tuning | MT5(base,FT) | 37.21 | 75.12 | 56.17 |
| DITING(6B,LoRA,ChatGLM) | 32.97 | 77.69 | 55.33 | |
| DITING(6B,P-tuning,ChatGLM) | 34.12 | 78.23 | 56.18 | |
| LLaMA(7B, LoRA) | 29.67 | 78.54 | 54.11 | |
| Alpaca(7B,LoRA) | 34.73 | 81.45 | 58.09 | |
| Alpaca(13B,LoRA) | 39.16 | 82.39 | 60.78 | |
| KnowLM(13B,LoRA) | 49.21 | 85.72 | 67.47 | |
| DITING(13B,LoRA,KnowLM) | 56.47 | 79.61 | 68.04 | |
| In-Context Learning | ChatGPT(5 shot) | 40.72 | 73.43 | 57.08 |
由于我们和InstructIE的作者进行微调的数据并不相同,所以并不能进行非常科学的技术性比较。但是我们可以从模型的结果中观察到一定的规律和经验。
没有经过微调的大模型并不适合图谱构建任务(三元组抽取): 大模型在只进行了5个随机提示的情况下准确率就能够达到一个较好的水平,说明其具有很强的用于抽取的潜力,能够理解并提取文本中的待抽取信息。然而大模型面临抽取界限错误、抽取信息不完整、生成幻觉等问题,使其ROUGE-2值低于表中的所有其他模型
任务数据的微调能大幅度提升模型在具体任务的性能: 在经过微调过后,即使是较小的模型也能在特定任务上超越性能强大的ChatGPT模型,说明上下文学习并不能很好的让模型学会完成特定的下游任务、提供相关知识。特定任务的微调才能更好的激发模型的能力。
模型的基础能力决定了性能的上限: 模型的F1分数和预训练模型的大小、能力有着较强的相关关系。当使用更大的模型作为基底进行微调时,如Alpaca(13B,LoRA)与Alpaca(7B,LoRA)对比,性能有全方面的稳定提升。由于Alpaca中的中文数据较少,所以Alpaca作为基础模型的中文能力不足。因此在微调效果上,使用中文数据进行增量预训练的CaMA(13B,LoRA)有着全方位的大量提升。这说明微调数据和预训练数据保持多样性和配比一致的重要性,也体现出模型的主要能力来自于预训练,而格式约束、任务对应主要来自于微调。
多样化的指令能够提升模型在具体任务上的性能: LLaMA(7B, LoRA)和Alpaca(7B,LoRA)基于相同的模型,但由于Alpaca包含 52K 指令跟随演示的数据集上进行微调,导致理解和遵守指令的能力增强,使其在 InstructIE 上显示出卓越的性能。ChatGLM(6B,P-tuning,Ours) 和ChatGLM(6B,LoRA,Ours) 对比性能更强,不仅是因为微调方法的原因,也是因为我们在微调第二版的过程中进行了全方面的数据增强,更多元化的指令激发了模型更好的性能。
**全参数微调相较于P-tuning和LoRa等低参数微调方法,能更好的激发模型的能力:**MT5 模型进行微调产生的结果与 LoRA 在大得多的模型上产生的结果相当。与包含所有参数调整的微调相比,如果不能很好地设计LoRa,有选择地修改模型参数的一小部分并不是十分有效。
我们的模型在比赛中取得第一名的成绩,较大幅度超越了baseline,取得了较有竞争力的性能。
错例分析
| 错误类型 | 错例 |
|---|---|
| 抽取不完整 | 输入:广原站位于宫崎县西诸县郡高原町,是九州旅客铁道(JR九州)吉都线上的车站。 输出:(广原站,位于,高原町),(高原町,位于,宫崎县) 标签:(广原站,位于,高原町),(宫崎县,位于,西诸县郡),(西诸县郡,位于,高原町),(高原町,位于,宫崎县) |
| 重复生成 | 输入:大劳拉钟楼是乌克兰首都基辅洞窟修道院的一座钟楼,也是基辅天际线的最著名的地标之一。输出:(大劳拉钟楼,位于,基辅),(大劳拉钟楼,位于,基辅),(大劳拉钟楼,位于,基辅)标签:(大劳拉钟楼,位于,基辅),(基辅,位于,乌克兰) |
| 边界抽取错误 | 输入:洛社站是一个京沪线上的铁路车站,位于江苏省无锡市惠山区洛社镇,邮政编码为214187。输出:(洛社站,位于,洛社)标签:(洛社站,位于,洛社镇) |
| 无关生成 | 输入:乙训寺是京都府长冈京市的真言宗丰山派寺院。以牡丹之寺为人所知。输出:(牡丹之寺,临近,乙训)标签:(乙训寺,位于,长冈京市) |
如上图,我们整理了一些模型在完成生成任务中的经典错例。大致可以分为抽取不完整、重复生成、边界抽取错误、无关生成几个类型。从原因上进行分析:
- 数据问题:大型生成式语言模型通常需要大量的高质量数据进行训练,然而在信息抽取领域的数据往往存在缺失、噪声和难以处理的情况。此外,数据中的实体边界、关系标注等人工标注也可能存在错误或者不一致的问题,这些都会对模型在抽取实体边界、关系等方面造成困扰。
- 模型设计问题:大型生成式语言模型通常采用基于TransformerDecoder的结构。这类自回归生成结构在处理长序列或跨度较大的实体边界或关系时,会存在幻觉、前后文依赖性建模错误等,最终导致重复生成、抽取不完全等问题。
- 微调数据不足:微调是通过特定数据集来优化模型,在信息抽取领域中,这些微调数据往往规模较小,难以覆盖到真实世界中各种实体和关系,因此微调效果有限。同时,微调数据可能与真实世界中的数据存在差异,或者与测试数据不匹配,这也会影响模型的性能。
- 预训练模型任务抽象能力有限:预训练模型的目的是通过大规模的无监督任务进行训练,然后在特定任务上进行微调,以提升性能。但是,预训练模型往往在训练过程中往往缺少信息抽取数据,而对于实体边界、关系等抽象概念到的学习能力有限,这也会导致模型在信息抽取领域出现抽取错误、无关生成等问题。
引用
Wei, X., Cui, X., Cheng, N., Wang, X., Zhang, X., Huang, S., Xie, P., Xu, J., Chen, Y., Zhang, M., Jiang, Y., & Han, W. (2023). Zero-Shot Information Extraction via Chatting with ChatGPT (arXiv:2302.10205).
Wang, X., Zhou, W., Zu, C., Xia, H., Chen, T., Zhang, Y., Zheng, R., Ye, J., Zhang, Q., Gui, T., Kang, J., Yang, J., Li, S., & Du, C. (2023). InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction (arXiv:2304.08085).
Gui, H., Zhang, J., Ye, H., & Zhang, N. (2023). InstructIE: A Chinese Instruction-based Information Extraction Dataset (arXiv:2305.11527).
Sun, T. X., Liu, X. Y., Qiu, X. P., & Huang, X. J. (2022, May 28). Paradigm Shift in Natural Language Processing. Machine Intelligence Research, 19(3), 169–183.
Lu, Y., Liu, Q., Dai, D., Xiao, X., Lin, H., Han, X., Sun, L., & Wu, H. (2022). Unified Structure Generation for Universal Information Extraction. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
Lu, Y., Lin, H., Xu, J., Han, X., Tang, J., Li, A., Sun, L., Liao, M., & Chen, S. (2021). TEXT2EVENT: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers).
Wei, Z., Zhao, Y., Lu, K., Zhou, G., Xu, J., & Yan, J. (2022). Finetune Language Models are Zero-Shot Learners. ICLR.
Ouyang, X., Li, M., Liu, S., Li, P., Tang, J., & Zhou, G. (2023). Training Language Models to Follow Instructions with Human Feedback. arXiv preprint arXiv:2203.02155.
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2021). Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey. arXiv preprint arXiv: 2111.01243.
Wang, X., Li, S., & Ji, H. (2022). Code4Struct: Code Generation for Few-Shot Structured Prediction from Natural Language. arXiv preprint arXiv:2210.12810.
Gutiérrez, B. J., McNeal, N., Washington, C., Chen, Y., Li, L., Sun, H., & Su, Y. (2022). Thinking about GPT-3 In-Context Learning for Biomedical IE? Think Again (arXiv: 2203.08410)
Ma, Y., Cao, Y., Hong, Y., & Sun, A. (2023). Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples!. arXiv preprint arXiv:2303.08559.
Qian, C., Han, C., Fung, Y. R., Qin, Y., Liu, Z., & Ji, H. (2023). CREATOR: Disentangling Abstract and Concrete Reasonings of Large Language Models through Tool Creation. arXiv preprint arXiv: 2305.14318.
Liu, X., Ji, K., Fu, Y., Tam, W. L., Du, Z., Yang, Z., & Tang, J. (2021). P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks. arXiv preprint arXiv:2110.07602.
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv: 2106.09685.
Qin, Y., Hu, S., Lin, Y., Chen, W., Ding, N., Cui, G., Zeng, Z., Huang, Y., Xiao, C., Han, C., Fung, Y. R., Su, Y., Wang, H., Qian, C., Tian, R., Zhu, K., Liang, S., Shen, X., Xu, B., … Sun, M. (2023). Tool Learning with Foundation Models (arXiv:2304.08354).
Li, P., Sun, T., Tang, Q., Yan, H., Wu, Y., Huang, X., & Qiu, X. (2023). CodeIE: Large Code Generation Models are Better Few-Shot Information Extractors (arXiv:2305.05711).
Ma, Y., Cao, Y., Hong, Y., & Sun, A. (2023). Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples! (arXiv: 2303.08559).
Jiang, Z., Xu, F. F., Araki, J., & Neubig, G. (2019). How Can We Know What Language Models Know?. arXiv preprint arXiv: 1911.12543.
- 研究动机及本工作的差异性
- 系统介绍
- 整体流程
- 数据集构建
- 数据源
- IE 指令数据
- CCKS InstructionKGC
- 自收集数据
- 数据准备
- 指令构建
- 指令微调框架
- 评估方法
- 结果分析
- CCKS 图谱构建任务
- 错例分析
- 引用